I don't want to edit the history.
I want to edit the bleeding log message.
F**k hg.
Version control the old log message, for sure.
But don't make me use a bleeding sledgehammer, history editing, to change the commentary.
--
Is history what happened, or is it the commentary on what happened? Historians write the latter.
Thursday, May 31, 2012
Friday, May 25, 2012
Debugging
I often still debug via printf. Or, rather, via other code that eventually calls printf.
I used to feel guilty about this, embarassed that I did not always use a debugger like gdb. But then I heard some famous programmers say "I debug using printf".
Even better, since I started doing Agile, I spend less and less time debugging. (Conversely, when I work with legacy code, code that doesn't have tests, I spend more time debugging.)
Now, I have gotten better at using debuggers like gdb over the years. And some of my "add code" debugging cooperates well with debuggers like gdb.
For example, many many years ago another student/lab manager/research assistant/TA (who I think is reading this blog - thanks, Steve) said that he was in the habit of writing data structure printing tools and consistency checks, even if not used in his "production" code - if for no other reason than to be able to call them from a debugger. To this I add that such code is often also useful in automated unit tests. (Diffing taking into account hex addresses...) And also useful if you have to fallback to printf debugging.
What I like about printf debugging is that it often develops assets, code that can be reused. Both for future debugging, and for other purposes.
Whereas gdb style debugging often does not. Yes, you can write debug scripts - e.g. I found some useful scripts that can dump STL datastructures in a nice manner, rather than in the unreadable manner that so many debuggers print them. So-called symbolic, but not very high level.
Even better, since I started doing Agile, I spend less and less time debugging. (Conversely, when I work with legacy code, code that doesn't have tests, I spend more time debugging.)
Now, I have gotten better at using debuggers like gdb over the years. And some of my "add code" debugging cooperates well with debuggers like gdb.
For example, many many years ago another student/lab manager/research assistant/TA (who I think is reading this blog - thanks, Steve) said that he was in the habit of writing data structure printing tools and consistency checks, even if not used in his "production" code - if for no other reason than to be able to call them from a debugger. To this I add that such code is often also useful in automated unit tests. (Diffing taking into account hex addresses...) And also useful if you have to fallback to printf debugging.
What I like about printf debugging is that it often develops assets, code that can be reused. Both for future debugging, and for other purposes.
Whereas gdb style debugging often does not. Yes, you can write debug scripts - e.g. I found some useful scripts that can dump STL datastructures in a nice manner, rather than in the unreadable manner that so many debuggers print them. So-called symbolic, but not very high level.
assert/ignore pattern
Here's a pattern I observed today. I have seen it before. (In my wont to record neat little tidbits that m,ay be worthy of further thought.)
Started with code:
Object* objptr = ...;
assert( objptr->consistency_check() );
assert( objptr->fooptr->consistency_check() );
assert( more_consistency_checks(objptr) );
... do something with objptr ...
Now, often enough it might be correct not to error exit with an assert. Often enough, in my problem domain, if one of the consistency checks fails you can just ignore the object, and go on.
In my domain, computer architecture, this may arise because of speculative execution.
So, pseudo-equivalent code might look like
Object* objptr = ...;
if( ! objptr->consistency_check() ) {
}
else if( ! objptr->fooptr->consistency_check() ) {
}
else if( ! more_consistency_checks(objptr) ) {
... do something with objptr ...
}
I know, you might prefer
Object* objptr = ...;
if( objptr->consistency_check()
&& objptr->fooptr->consistency_check()
&& more_consistency_checks(objptr) ) )
{
... do something with objptr ...
}
but I have found that I often want to do stuff like keep stats for which forms of inconsistencies were found,
i.e. which assert would have failed if we had been failing.
Or
Object* objptr = ...;
try {
assert( objptr->consistency_check() );
assert( objptr->fooptr->consistency_check() );
assert( more_consistency_checks(objptr) );
... do something with objptr ...
} catch(...) {
...
}
although it can be unfortunate if the catch is a long way away from the assert.
You might want to specify the assert fail action at the assert - which is what the OF statements do.
---
No biggy, just a pattern I have seen before.
Thursday, May 24, 2012
Rewriting history in version control systems
Some people like rewriting history in version control systems.
These people do not want "history" - they do not want an accurate record of events. They want a "narrative", an arc of development. With some of the ugliness and irregularity of what actually happened removed.
--
Recently overheard: "Oh, we can't go back to the version used for that test, because somebody rewrote history."
--
My take, as explained earlier:
Record the history. The real, raw, history. (Heck, I am occasionally willing to check in broken code - on a branch., NOT into the main line. NOT released to others.
E.g. sometimes it is worth recording, in the project history, all of the standing upon your head that you had to do to work around compiler bugs.)
But clean up the history, the logs, the narrative, when releasing. Merging back into parent branch. Etc.
And teach people how to look at the cleaned up history, the narrative. And only have to look at all the details if absolutely necessary.
--
A simple example of a narrative versus history:
It sometimes happen that two features are implemented in an interleaved manner:
Feature A - first step
Feature B - first step
Feature A - second step
Feature B - second step
Now, while it would be nice if somebody created separate branches for feature A and feature B, we all know it doesn't always happen. That is why we may be rewritging the history, cleaning up the narrative.
It may look better as
Feature A - first step
Feature A - second step
Feature B - second step
Feature B - first step
i.e. do both steps of Feature A, then both steps of Feature B.
Or even, retroactively create separate branches.
This can actually be accomplished by creating new branches, selectively patched and merged.
But, it may not be worth the work to do this.
But it may be worth the work to record the narrative showing it. So long as the actual history is also stored.
Heck, perhaps tools could make it easier to reconstruct the narrativem, as it woulda/coulda/shoulda happened. Albeit with a warning "This is not an actual historical reconstruction, so it may not actually work".
Sunday, May 20, 2012
file.ext and file.ext-DIR/ versus file and file/file
I learned a long time ago that what starts out as a single file often becomes a directory.
E.g. one of my first "open source" things was my debug header, debug.h. Standardly ~/src/libag/debug.h
But many years later I drank the koolaid of testing, so I wanted debug-test.c. And a Makefile. Where did I put it?
Separate files makes it easy to copy debug.h without the tests:
~/src/libag
debug.h
debug-test.c
Makefile
some-other-lib-header.h
And the Makefile would have to have stuff for all the things in the same directory. Messy.
So I learned that it was good to create "directory objects" for such things. Places where all of the usual things, e.g., associated with a single header-only library fo:
tests, Makefiles, README, man pages, etc.:
~/src/libag
debug/
debug.h
debug-test.c
Makefile // just for debug.g
some-other-lib-header
some-other-lib-header.h
test-some-other-lib-header.c
Makefile // just for some other lib header
So, all is happy. It is slightly annoying to have to type debug/debug.h, as in
#include "debug/debug.h"but I am willing to do so to get the goodness of directory objects. But then I encounter... barbarians. Tools that do not use "directory objects". E.g. I recently had to debug my X windows setup. I'm learning that even simple stuff in something like a .twmrc needs tests. Where do I but them? .twmrc is in a directory, ~/, shared by many tools. Convention: create .twmrc.DIR, and put the stuff in there. Generalization: given a file "file" that is not by itself in a directory "file/file", create "file.DIR/" as the place to hold such meta-information. === It might be nice to make this transparent: Create a file "file", and let it live without the stuff that I put in the accompanying or enclosing directory. As long as it needs to. But when it comes time to create the accompanying stuff, the meta stuff, like READMEs and manual pages and tests and examples and makefiles... - allow file.DIR top be created. (Or cvall it file.meta, or ...). But make file and file.DIR semi-transparent. If you do "cp file dest ", then it is equivalent to "cp -R file file.DIR dest". Or, rather, perhaps, use the old concept of filesystem forks, such as resource forks. Make "file" be an alias for "file.DIR/file".
Saturday, May 19, 2012
X widgets bad sizes in twm RightTitleButton due to LANG=en_US.UTF-8 fixed by unsetting LANG or setting LANG=C
Since I got to my current employer last October, I have been suffering problems with my X setup.
First: admission: I still use twm. Or, rather: twm has been my fallback window manager for years, when other X setup breaks. As it so often does.
Instead of the widgets at the top of my windows being nice and compact:

They were "blown up":
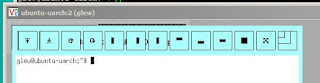
This was particularly painful when working on my tablet PC, 1366x768. Too much screen space lost. Got in the way of doing useful work.
I have avoided the problem all this time, 8 months, by not using my laptop except when plugged into external monitors with lots of pixels.
Well, this week I away from my external monitors. So I figured out what the problem was.
By process of elimination:
The problem that was causing the twm RightTitleButtons to be too large was due to
LANG=en_US.UTF-8
When I unset LANG, or set LANG=C (as I have had to do elsewhere), twm works properly.
Why? I dunno.
Why do I have LANG set to en_US.UTF-8? I dunno - it was default.
--
glew@ubuntu-uarch:~$ uname -a
Linux ubuntu-uarch 2.6.32-33-generic #72-Ubuntu SMP Fri Jul 29 21:07:13 UTC 2011 x86_64 GNU/Linux
But also occurred on CentOS and RedHat.
--
Some text that might make it easier to find this bug and fix:
X widgets bad sizes
in twm RightTitleButton
due to LANG=en_US.UTF-8
fixed by unsetting LANG or setting LANG=C
First: admission: I still use twm. Or, rather: twm has been my fallback window manager for years, when other X setup breaks. As it so often does.
Instead of the widgets at the top of my windows being nice and compact:

They were "blown up":

This was particularly painful when working on my tablet PC, 1366x768. Too much screen space lost. Got in the way of doing useful work.
I have avoided the problem all this time, 8 months, by not using my laptop except when plugged into external monitors with lots of pixels.
Well, this week I away from my external monitors. So I figured out what the problem was.
By process of elimination:
The problem that was causing the twm RightTitleButtons to be too large was due to
LANG=en_US.UTF-8
When I unset LANG, or set LANG=C (as I have had to do elsewhere), twm works properly.
Why? I dunno.
Why do I have LANG set to en_US.UTF-8? I dunno - it was default.
--
glew@ubuntu-uarch:~$ uname -a
Linux ubuntu-uarch 2.6.32-33-generic #72-Ubuntu SMP Fri Jul 29 21:07:13 UTC 2011 x86_64 GNU/Linux
But also occurred on CentOS and RedHat.
--
I hate internationalization bugs. Mainly because I worked on pre-POSIX internationalization, and *my* system never had such bugs. ;-}
--
Some text that might make it easier to find this bug and fix:
X widgets bad sizes
in twm RightTitleButton
due to LANG=en_US.UTF-8
fixed by unsetting LANG or setting LANG=C
Wednesday, May 16, 2012
Stupid Programming Bugs
I will start trying to cllect stupid programming bugs that I have wasted my time on.
Especially if I did not google the answer the first time.
http://wiki.andy.glew.ca/wiki/Stupid_Programming_Bugs
http://wiki.andy.glew.ca/wiki/Forgetting_to_flush_stdout_and_stderr_before_fork
Now I'll expose how stupid a programmer I can be.
By recording stupid timewasting bugs that I should have known better about.
So that, I hope, I will be able to google them if I repeat the bug
Ditto others.
Thursday, May 10, 2012
Disambiguating names according to scopes in C++
Consider
var .
Have the IDE warn if an edit would change the implicit sigil. Much as GCC warns if an inner scope hides an outer scope's name.
int biff;
int var;
struct Var {
int var;
void foo(int var) {
biff = var;
}
};
Which var is used in the assignment?
Sure, a good C++ programmer knows the rules. But it can be hard to tell in a large program.
You can disambiguate for the member
biff = this->var;
or the global
biff = ::var;
But so far as I know there is no syntax for arguments. I often use a naming convention
void foo(int arg_var) {
this->var = arg_var;
}
This is not unlike the widespread convention of saying
void foo(int arg_var) {
m_var = arg_var;
}
although I deprecate this because m_var for member names can lie - there may be a global of that name. Whereas this-> is not much bigger, and has the compiler check your meaning.
Perhaps there should be sigils, like this-> and ::, for arguments and locals?
--
Late addition, 5/25/2012:
I dislike extra typing. Plus, occasionally I will do a refactoring where an arg or a global becomes a local or a member. Sometimes I want such refactorfings to show up in history diffs, sometimes not.
Here's an interesting possibility: have the build or ODE system annotate the code with a hidden sigil (which I would suggest being XML, something like Wednesday, May 09, 2012
xpra
---+ rootless shareable and transportable X sessions.
For a long time I have been frustrated by VNC's putting all of the application windows in a big window for the X root. It always seemed to me that you could have an X server that kept all of the windows separate - perhaps by having an infinitely resizable root - which then allows the windows to be forwarded to the user's display (I think of that as a client, but in X terms it is a display server), and treated independently there.
I'm not the only one. Googling finds many people looking for "screen for X". I guess I betray my age when I admit that my desire for this predates GNU screen and VNC. I remember being happy when I encountered GNU screen's terminal multiplexer, since I had used similar tools elsewhere. (By the way, while I am at it: I recently started trying to use GNU screen, after a long lapse. One of my complaints is that GNU screen seems to be screen. I vaguely remember a terminal multiplexer that handled dumb terminals well enough, allowing you to connect separate terminal emulators, as well as other stuff.)
Anyway: screen for X...
I have looked at NX, xmove, etc., at various times, all with differing degrees of clunkiness. Nothing made mwe happy until...
---+ xpra
Hurrah for xpra! http://xpra.org/
xpra allows you to send applications from one display to another. On an application by application basis. (Hmm, I wonder what happens to a multi-window application.)
I am happy that IT finally has a system on which they were willing to install xpra.
---+ Winswitch? not yet, maybe not ever
I am considering winswitch, http://winswitch.org/, which is layered on top of xpra or VNC or RDP or ssh -X or NX or ...
But I am not jumping at winswitch the way I am jumping at xpra, since (a) I don't want yet another insecure password system, and (b) it seems to depend on all sides running winswitch.
---+ xpra does NOT need to be installed on both sides
Typically xpra usage examples say
http://xpra.org/:
https://help.ubuntu.com/community/Xpra:
I.e. they assume that xpra is installed both on the server and on the client.
(Urg, confusing terminology. There are 3 important systems here: (1) the system where the xpra proxy server runs, (2) the system where the application software runs, and (3) the system where the display runs.)
This was a worry, since I often want to move applications to a system that may have X, but which may not have xpra on. E.g. Cygwin/X on my Windows PC. (I considered Winswitch for this, but it requires itself to be installed in too many places.)
I am happy to say that you do NOT need to have xpra installed on the display system. E.g.
For a long time I have been frustrated by VNC's putting all of the application windows in a big window for the X root. It always seemed to me that you could have an X server that kept all of the windows separate - perhaps by having an infinitely resizable root - which then allows the windows to be forwarded to the user's display (I think of that as a client, but in X terms it is a display server), and treated independently there.
I'm not the only one. Googling finds many people looking for "screen for X". I guess I betray my age when I admit that my desire for this predates GNU screen and VNC. I remember being happy when I encountered GNU screen's terminal multiplexer, since I had used similar tools elsewhere. (By the way, while I am at it: I recently started trying to use GNU screen, after a long lapse. One of my complaints is that GNU screen seems to be screen. I vaguely remember a terminal multiplexer that handled dumb terminals well enough, allowing you to connect separate terminal emulators, as well as other stuff.)
Anyway: screen for X...
I have looked at NX, xmove, etc., at various times, all with differing degrees of clunkiness. Nothing made mwe happy until...
---+ xpra
Hurrah for xpra! http://xpra.org/
xpra allows you to send applications from one display to another. On an application by application basis. (Hmm, I wonder what happens to a multi-window application.)
I am happy that IT finally has a system on which they were willing to install xpra.
---+ Winswitch? not yet, maybe not ever
I am considering winswitch, http://winswitch.org/, which is layered on top of xpra or VNC or RDP or ssh -X or NX or ...
But I am not jumping at winswitch the way I am jumping at xpra, since (a) I don't want yet another insecure password system, and (b) it seems to depend on all sides running winswitch.
---+ xpra does NOT need to be installed on both sides
Typically xpra usage examples say
http://xpra.org/:
On the machine which will export the application (xterm in this example):
xpra start :100
DISPLAY=:100 xterm
xpra attach :100
xpra attach ssh:serverhostname:100https://help.ubuntu.com/community/Xpra:
- Start an xpra server using display number :7.
- Start firefox running inside the xpra server. No window will appear.
- Show a list of xpra servers you have running on the current host.
- Attach to the xpra server that is using local display number :7. Any apps running on that server will appear on your screen.
- Use ssh to attach to the xpra server that is running on machine frodo and using display :7. Any apps running on that server will appear on your local screen.
- Start an xpra server and a screen(1) session. If any of the applications inside screen attempt to use X, they will be directed to the xpra server.
- Stop the xpra server on display number :7.
xpra start :7
DISPLAY=:7 firefox
xpra list
xpra attach :7
xpra attach ssh:frodo:7
xpra start :7 && DISPLAY=:7 screen
xpra stop :7
I.e. they assume that xpra is installed both on the server and on the client.
(Urg, confusing terminology. There are 3 important systems here: (1) the system where the xpra proxy server runs, (2) the system where the application software runs, and (3) the system where the display runs.)
This was a worry, since I often want to move applications to a system that may have X, but which may not have xpra on. E.g. Cygwin/X on my Windows PC. (I considered Winswitch for this, but it requires itself to be installed in too many places.)
I am happy to say that you do NOT need to have xpra installed on the display system. E.g.
Monday, May 07, 2012
MS Outlook 2010 text selection bug - and "fix"
For quite some time now, I have been terribly frustrated using MS Outlook 2010. It was not allowing me to select text in messages that I was reading, neither in a preview pane, now in a proper reading window.
I was only able to select text if I hit reply. In the reply email composition window I could select text.
This was frustrating.
Eventually I learned that if I hot ESCape (and possibly capslock toggle), them I could get to a mode where I could select text in a reading window.
The discussion at the following MS URL helped:
Helped. Did not describe the fix precisely, although it seems that others may have followed the same path. One poster kept asking "Does your cursor look like a hand?", and then suggested hitting ESCape.
Well, my cursor did not look like a hand. But hitting ESCape fixed the problem anyway.
--
Sheesh, when I think of all the time I have wasted hitting reply to select and copy text...
Wednesday, May 02, 2012
PDX recycling
New house, new trash and recycling service. Since I try to be green, but often have trouble find where to recycle, recorded here:
Several different relevant websites:
- City of Portland, http://www.portlandonline.com
- Annoyingly, Portland's web pages use non-human-intelligible URLs, like ?c=41467. I hate this!
- Rates and service: http://www.portlandonline.com/bps/index.cfm?c=41467
- Schedule: http://www.portlandonline.com/bps/index.cfm?c=54938
- Seasonal: http://www.portlandonline.com/bps/index.cfm?c=41471
- Xmas tree: http://www.portlandonline.com/bps/index.cfm?c=41471&a=109113
- basically, can put whole tree out on curb 4$/6$>8 feet
- or cut into pieces, in green compost bin, or separate bundles for 3.75$
- Waste Management, http://wmnorthwest.com/portland
- Lists of what can and cannot be taken are on web pages, although not all in one place
- Garbage: http://www.portlandonline.com/bps/index.cfm?c=55401
- Recycling: http://wmnorthwest.com/portland/recycling.html, http://www.portlandonline.com/bps/index.cfm?c=44752
- no plastic lids, no plastic bags
- Compost: http://wmnorthwest.com/portland/yardwaste.html, http://www.portlandonline.com/bps/index.cfm?c=47246
- most food waste, but not packaging
- most yard waste
- no plastic bags
- no pet waste
- Tough Stuff
- Plastic bags - NOT curbside. Recycle depots, some grocery stores
- Styrofoam blocks - ??? - Curbside trash (but often too big, e.g. for a big package) :-(
- Styrofoam packing peanuts - UPS. Not Fedex. Not recycling depots. Curbside trash.
- Electronic - NOT curbside. Some recycling depots
- Pet poop - trash
- Waste Management's "Think Green" program, http://thinkgreenfromhome.com/
- for stuff that doesn't get picked up curbside
- call to ask for mail-back boxes for
- batteries, 19.95$ / 4 lb
- lightbulbs (incandscent, CFL, and LED), 19.95$ / 13
- actually, web page implies only needed for CFL, mercury.
- medical waste (e.g. diabetes blood test kits, lancets, and/or needles and syringes), 45-55$
- curbside, by special arrangement, an option in Portland
- big fluorescent tubes, 69.95$ / circa 16 bulbs
Tuesday, May 01, 2012
Comments at beginning of line?
code; // we have comments at the end of a line
code /* and comments anywhere on a line, like in the middle */ code;
/* where "anywhere" can be at the beginning: */ code;
but it occurs to me that I often want comments at the beginning of a line, e.g.
foo(
/* arg1= */ 111,
/* arg2= */ 222,
)
and although /*...*/ can accomplish this, they are visually heavyweight.
I wonder if, in a hypothetical new language, we could have comments from the beginning of a line?
Now, ":" would be the most natural comment delimiter for this - if it were not already used for so much else:
foo(
arg1: 111,
arg2: 222,
)
Note that I have distinguished comments in a special color. One might say that such a special comment color is what we really want... I agree, and have discussed that elsewhere. But it is certainly traditional to have program text read monocolor:
foo(
arg1: 111,
arg2: 222,
)
Now, you might also argue that keyword arguments subsume the example above. Sure... but then I can create other examples that are not keyword arguments.
I can imagine comment from beginning of line delimiters other than colon, but none are quite so elegant:
foo(
arg1>>> 111,
arg2:>>> 222,
)
foo(
arg1==> 111,
arg2==> 222,
)
foo(
arg1::: 111,
arg2::: 222,
)
Again, we are limited by the ASCII, or UTF, character set.
code /* and comments anywhere on a line, like in the middle */ code;
/* where "anywhere" can be at the beginning: */ code;
but it occurs to me that I often want comments at the beginning of a line, e.g.
foo(
/* arg1= */ 111,
/* arg2= */ 222,
)
and although /*...*/ can accomplish this, they are visually heavyweight.
I wonder if, in a hypothetical new language, we could have comments from the beginning of a line?
Now, ":" would be the most natural comment delimiter for this - if it were not already used for so much else:
foo(
arg1: 111,
arg2: 222,
)
Note that I have distinguished comments in a special color. One might say that such a special comment color is what we really want... I agree, and have discussed that elsewhere. But it is certainly traditional to have program text read monocolor:
foo(
arg1: 111,
arg2: 222,
)
Now, you might also argue that keyword arguments subsume the example above. Sure... but then I can create other examples that are not keyword arguments.
I can imagine comment from beginning of line delimiters other than colon, but none are quite so elegant:
foo(
arg1>>> 111,
arg2:>>> 222,
)
foo(
arg1==> 111,
arg2==> 222,
)
foo(
arg1::: 111,
arg2::: 222,
)
Again, we are limited by the ASCII, or UTF, character set.
Subscribe to:
Posts (Atom)